Instead
of using a special character set for each language, the Unicode
standard makes it possible to use characters from different languages
at the same time. Unicode is a standard encoding defined
by the Unicode
Consortium that assigns a unique and platform-independant
code value to each character.
With
Windows NT Microsoft also began offering an infrastructure for
Unicode-aware software.
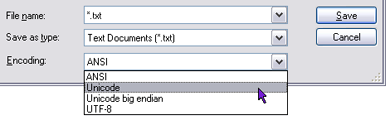
Whereas
each Unicode character has its own unique 2-byte character value,
there are several ways to physically store Unicode data in files:
· |
UTF-16 little endian:
A commonly used storage format. In the Notepad application
this format is simply called "Unicode." Each
character is stored as two bytes. The less significant
byte is stored first and the most significant byte second
(e.g., the character "E" (Unicode hexadecimal
value: 0045) is stored as "45 00"). |
· |
UTF-8: Another common
format. Storage of a character can range from one
to four bytes (e.g., the character "E" is stored
as "45" while the "em dash" character
(—)
(Unicode hexadecimal value: 2014) is stored as "e2
80 94"). |
· |
UTF-16 big-endian: Similar
to UTF-16 little endian in that each character takes two
bytes in storage. UTF-16 big-endian stores each
2-byte-value in the natural order (e.g., the character
"E" (Unicode hexadecimal value: 0045) is stored
as "00 45"). |
|